
"정렬 알고리즘"
개발을 하다보면 데이터를 어떤 순서로 처리하느냐 곧 기능이 되는 순간이 많다.
점수 순 리더보드, 인벤토리 정렬, 우선순위가 있는 작업 큐,
그리고 Unity에서 가까운 적부터 타겟팅 하는 로직까지 결국 정렬이 들어간다.
하지만 정렬도 다 같은 정렬이 아니다.
데이터 크기(n), 데이터 특성(정렬됨 또는 중복 많음), 안정성(동점 순서 유지),
추가 메모리 허용 여부에 따라 알고리즘 선택이 달라진다.
그래서 오늘은 대표 정렬 알고리즘들이 어떤 방식으로 동작하고,
각각을 언제 선택하면 좋은지를 정리해보려고 한다.
----------------------------------------------------------------------------------------------------------------------------------------------------------------
1) 정렬 알고리즘의 종류
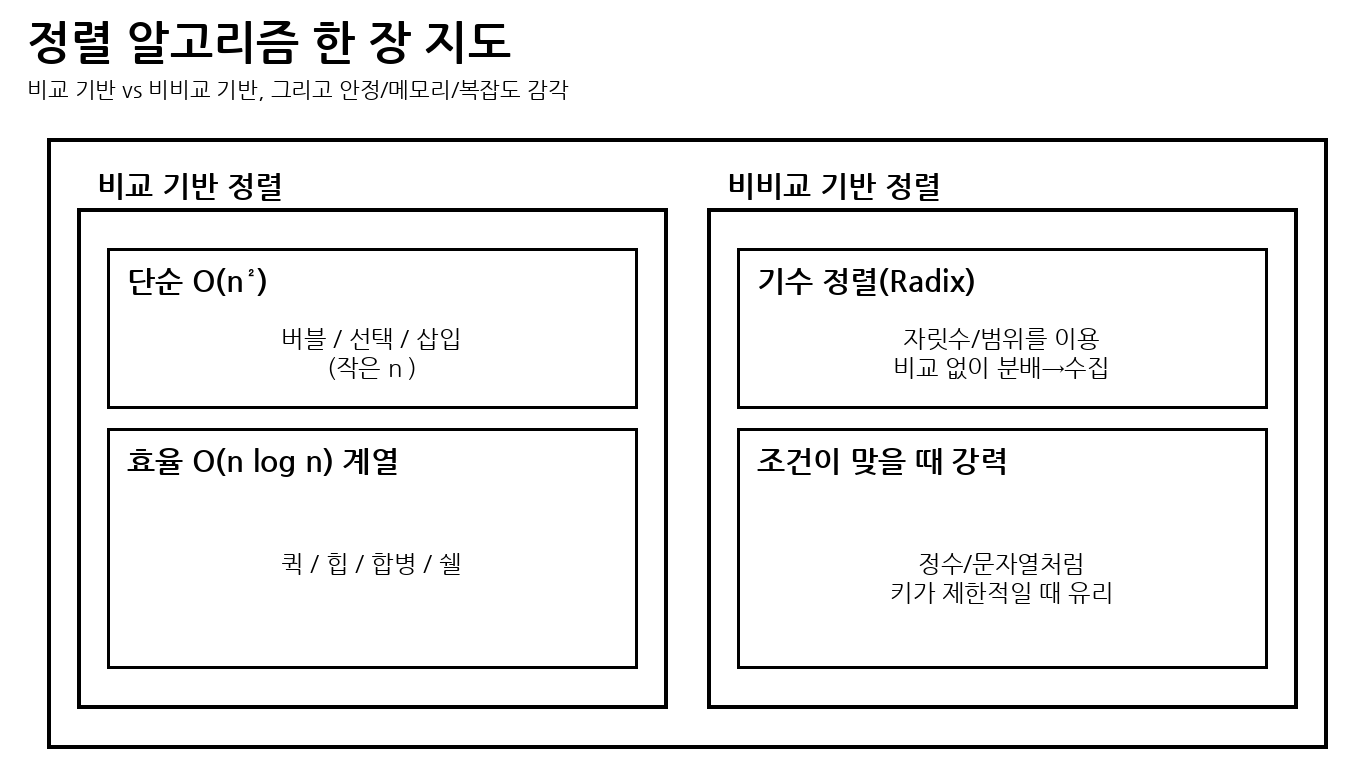
(1) 비교 기반 정렬(Comparison Sort)
두 값을 비교해서 순서를 정하는 방식
(버블/선택/삽입/쉘/퀵/힙/합병)정렬 등이 여기에 속한다.
(2) 비비교 기반 정렬(Non-comparison Sort)
값을 비교하지 않고 자릿수/범위 같은 키 특성으로 분배하는 방식
대표적으로 기수 정렬(Radix Sort)
----------------------------------------------------------------------------------------------------------------------------------------------------------------
2) 정렬 선택의 4가지 기준
a) 시간복잡도:
평균/최악이 얼마나 드는가?
b) 추가 메모리:
제자리(in-place)인가?, 추가 배열이 필요한가?
c) 안정성(Stable Sort):
값이 같은 요소의 원래 순서가 유지되는가?
d) 데이터 특성:
거의 정렬됨?, n이 작음?, 키 범위가 제한됨?

----------------------------------------------------------------------------------------------------------------------------------------------------------------
3) O(n²) 단순 정렬
(1) 버블 정렬(Bubble Sort)
인접한 두 원소를 비교해 큰 값을 뒤로 보내는 교환 과정을 반복하는 방식
평균 시간 복잡도 = O(n²)
최악 시간 복잡도 = O(n²)
안정성 = 안정 정렬(Stable) (인접 교환이므로 동점 순서 유지)
메모리 = O(1) (in-place)
(2) 선택 정렬(Selection Sort)
n개 중 최솟값(또는 최댓값)을 찾아 맨 앞(또는 뒤)에 놓고, 나머지에서 반복하는 방식
(교환 횟수는 적지만 비교가 많아 느림)
평균 시간 복잡도 = O(n²)
최악 시간 복잡도 = O(n²)
안정성 = 불안정 정렬(Unstable) (일반 구현 기준)
메모리 = O(1) (in-place)
(3) 삽입 정렬(Insertion Sort)
이미 정렬된(또는 정렬된 구간을 유지하는) 배열에 새 원소를 적절한 위치에 끼워 넣어 정렬하는 방식
(거의 정렬된 데이터에서는 매우 강함)
평균 시간 복잡도 = O(n²)
최악 시간 복잡도 = O(n²)
안정성 = 안정 정렬(Stable) (일반 구현 기준)
메모리 = O(1) (in-place)

----------------------------------------------------------------------------------------------------------------------------------------------------------------
4) O(n log n) 효율 정렬
정렬 대상이 커지거나(수백~수천 개),
정렬을 자주 해야 할수록 O(n log n) 계열을 사용한다.
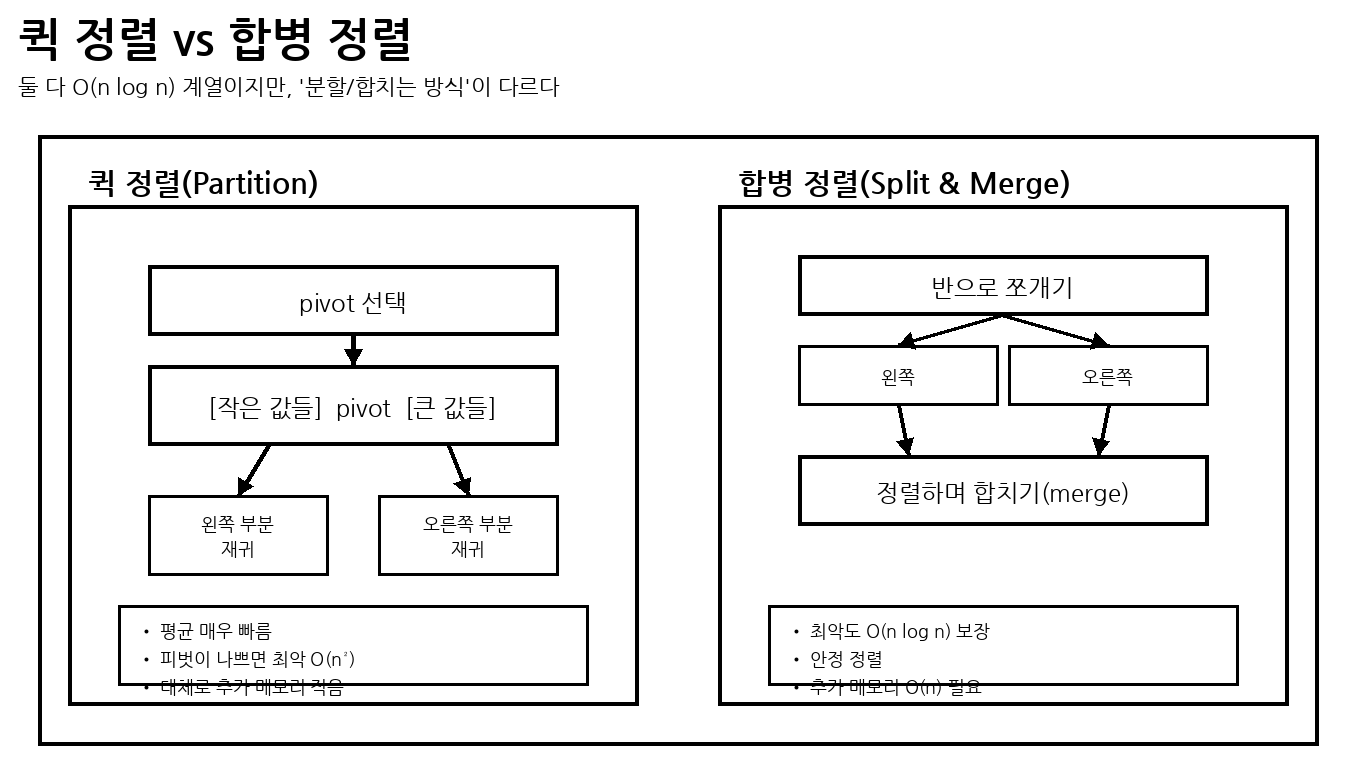
(1) 퀵 정렬(Quick Sort)
피벗을 기준으로 작은 값/큰 값을 좌우로 분할하는 과정을 반복하는 방식
(평균적으로 매우 빠르지만, 피벗이 나쁘면 최악 O(n²))
평균 시간 복잡도 = O(n log n)
최악 시간 복잡도 = O(n²)
안정성 = 불안정 정렬
메모리 = O(log n) (평균, 재귀 스택) / O(n) (최악, 재귀가 깊어질 때)
(추가 배열은 거의 없지만 재귀 호출 스택 공간은 사용)
(2) 합병 정렬(Merge Sort)
배열을 반으로 계속 나누고, 정렬된 부분 배열들을 정렬 및 병합하여 전체를 정렬하는 방식
평균 시간 복잡도 = O(n log n)
최악 시간 복잡도 = O(n log n)
안정성 = 안정 정렬
메모리 = O(n)
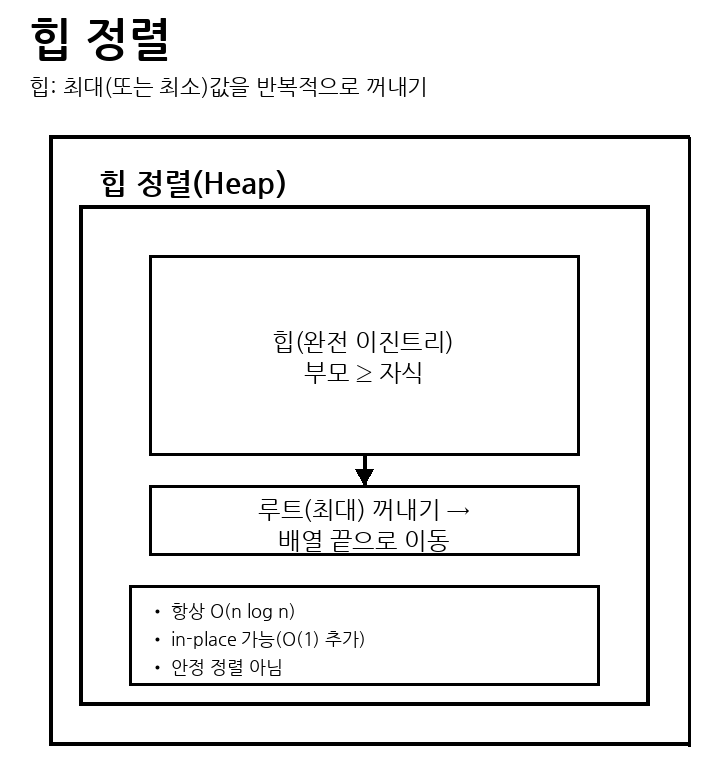
(3) 힙 정렬(Heap Sort)
완전 이진 트리 구조의 힙(Heap)을 만든 뒤,
루트(최대/최소)를 꺼내 배열 끝으로 보내며 반복하는 방식
평균 시간 복잡도 = O(n log n)
최악 시간 복잡도 = O(n log n)
안정성 = 불안정 정렬
메모리 = O(1)
(4) 쉘 정렬(Shell Sort)
일정 간격(gap)으로 떨어진 원소들을 묶어 부분 삽입 정렬을 수행하고,
gap을 줄여가며 반복하는 방식
(삽입 정렬의 개선)
평균 시간 복잡도 = gap 수열에 따라 다름
(대표적으로 ≈ O(n^1.3 ~ n^1.5) 로 설명하는 경우가 많음)
최악 시간 복잡도 = gap 수열에 따라 다름
(대표적으로 O(n²))
안정성 = 불안정 정렬
메모리 = O(1)
----------------------------------------------------------------------------------------------------------------------------------------------------------------
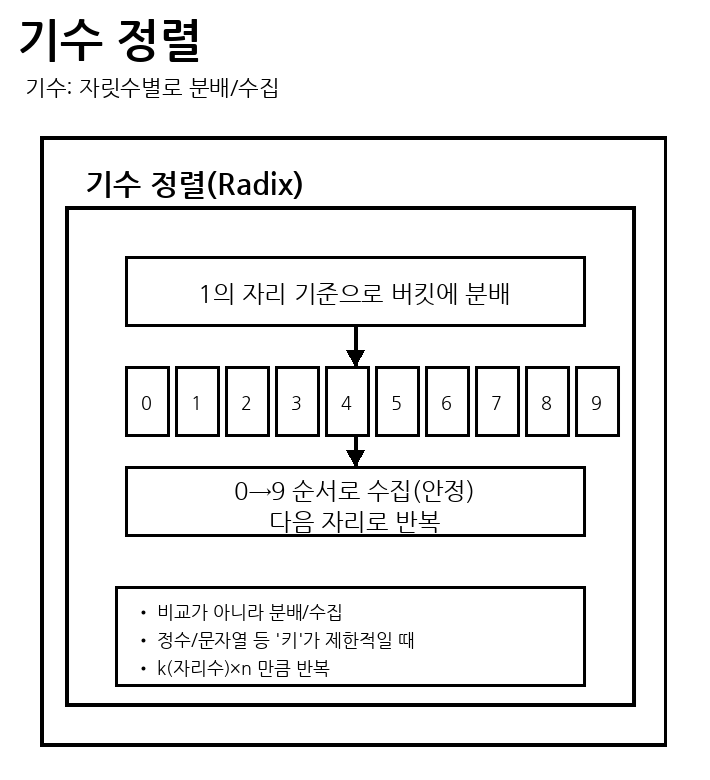
5) 비비교 기반: 기수 정렬(Radix Sort)
자릿수 또는 키의 자리/문자 위치를 기준으로 분배(버킷)
→ 수집을 반복해 정렬하는 비비교 기반 정렬
평균 시간 복잡도 = O(d·n)
(d=자리수/패스 횟수)
최악 시간 복잡도 = O(d·n)
안정성 = 보통 안정 정렬
(각 자릿수 정렬을 안정적으로 구현할 때)
메모리 = O(n + k)
(보조 배열/버킷/카운트 등, k=기수/범위)
----------------------------------------------------------------------------------------------------------------------------------------------------------------
6) 오늘의 한 줄 요약
『 정렬 알고리즘은 시간·메모리·안정성에 따라 ‘정렬을 어떻게 구현할지’를 선택하는 방법들이다. 』
'1일 1 cs' 카테고리의 다른 글
| 16. 그래프(Graph)와 트리(Tree)란? (0) | 2026.01.31 |
|---|---|
| 15. Fake Null 이란? (0) | 2026.01.30 |
| 13. 컬렉션(Collection)이란? (0) | 2026.01.28 |
| 12. 시간복잡도란? (0) | 2026.01.27 |
| 11. GC(Garbage Collector) 란? (0) | 2026.01.26 |